- Easy drag and drop capabilities
- Data collection
- Data preparation and cleaning
- Model building
- Data Visualization
- Model Deployment
- Integration with other tools and languages
- Employee Productivity: Who wants to spend days or weeks writing mundane code to load data, clean data, etc etc etc. No one wants to do this and especially employers don’t want their staff wasting time on this. Instead they are happy to invest in tools and workbenches where a lot or most or all of these mundane tasks are automated for you. You can not concentrate on the important tasks of adding value to your organisation. This saves money, improves employee productivity and employee value.
- Integration with Technical Architecture: Many of these tools and workbenches allow for easy integration with the technical architecture and thereby allowing easy and quick integration of machine learning withe the day to day activities of the organization. This saves money, improves employee productivity and employee value.
SAS software has been around for every and is the great grand-daddy of analytics and machine learning. They have built a large number of machine learning tools and solutions built upon these for various industries. Their core machine learning tools include SAS Enterprise Miner and SAS Visual Data Mining and Machine Learning.


Microsoft
Microsoft have been improving their Machine Learning offering over the years and most of this is based on the Azure cloud platform with Microsoft Azure Machine Learning Studio and Azure Databricks.


SAP
SAP Leonardo is a cloud based platform for machine learning and supports tight integration with other SAP software.


Oracle
Oracle have a number of machine learning tools and supports for the main machine learning languages. They have built a large number of applications (both cloud and on-premises) with in-built machine learning. Their main tools for machine learning include Oracle Data Miner, Oracle Machine Learning and Oracle Analytics (OAC or DVD versions)



Cloudera
If you work with hadoop and big data then you are probably using Cloudera in some way. Cloudera have hired Hilary Mason as their GM of ML. By taking an “AI factory” approach to turning data into decisions, you can make the process of building, scaling, and deploying enterprise ML and AI solutions automated, repeatable, and predictable—boring even. Cloudera Data Science Workbench is their solution.
IBM
IBM have a number of machine learning tools, one of them being a long standing member of the machine learning community, SPSS Modeler. Other machine learning tools include Watson Studio, IBM Machine Learning for z/OS, and IBM Watson Explorer.




Google have a large number of machine learning solutions including everything from traditional machine learning, into NLP, in Image processing, Video processing, etc. It’s a long list. Many of these come with various APIs to access these features. Most of these revolve around their Google AI Cloud offering. But sticking with the tools and workbenches we have AI Platform Notebooks, Kubeflow, and BigQuery ML.



TensorBoard
TensorBoard is a suite of tools for graphical representation of different aspects and stages of machine learning in TensorFlow.


Amazon
A bit like Goolge, Amazon has a large number of solutions for machine learning and AI, and most of these are available via an API or some cloud service. Amazon SageMaker is their main service.


Looker
Looker connects directly with Google BQML reduces additional complexity for data scientists by eliminating the need to move outputs of predictive models back into the database for use, while also increases the time-to-value for business users, allowing them to operationalize the outputs of predictive metrics to make better decisions every day.


Weka
Weka has been around for a long time and still popular in some research groups. Weka is a collection of machine learning algorithms for data mining tasks. It contains tools for data preparation, classification, regression, clustering, association rules mining, and visualization.



RapidMiner
RapidMiner Studio has been around for a long time and is one of the few more visual workflow tools (that everyone else should be doing).



Databricks
From the people who created Spark, we have another notebook solution for your machine learning projects called Databricks Workbench.


KNIME
KNIME Analytics Platform is the open source software for creating data science applications and services.


Dataiku
Dataiki Data Science (DSS) is a collaborative data science software workflow platform enabling data exploration, prototyping and delivery of analytical and machine learning solutions.

")
I’ve not included the tools like R Studio and Notebooks in this list as they don’t really address the aims listed above. But you will notice a lot of the above solutions are really Jupyter Notebooks. Most of these vendors have a long way to go to make the tasks of machine learning boring.
This list does not cover all available tools and workbenches, but it does list the most common one you will come across.
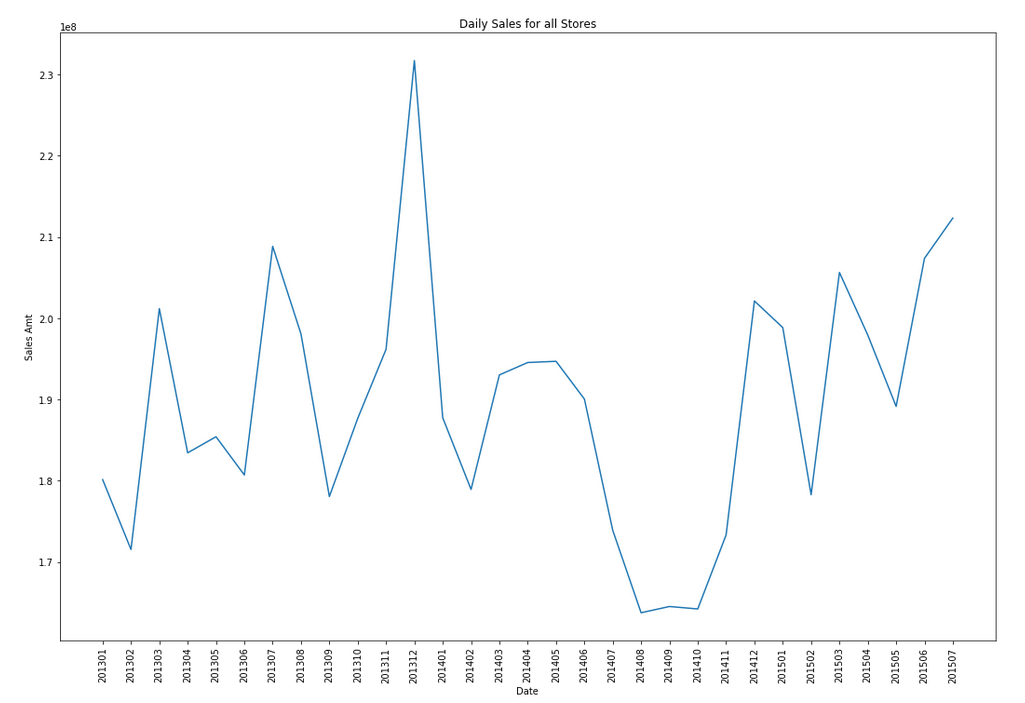
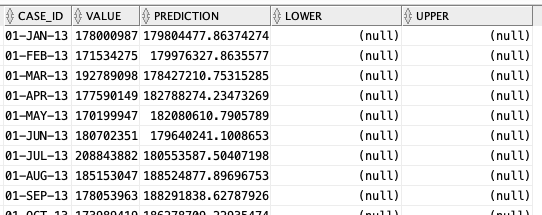
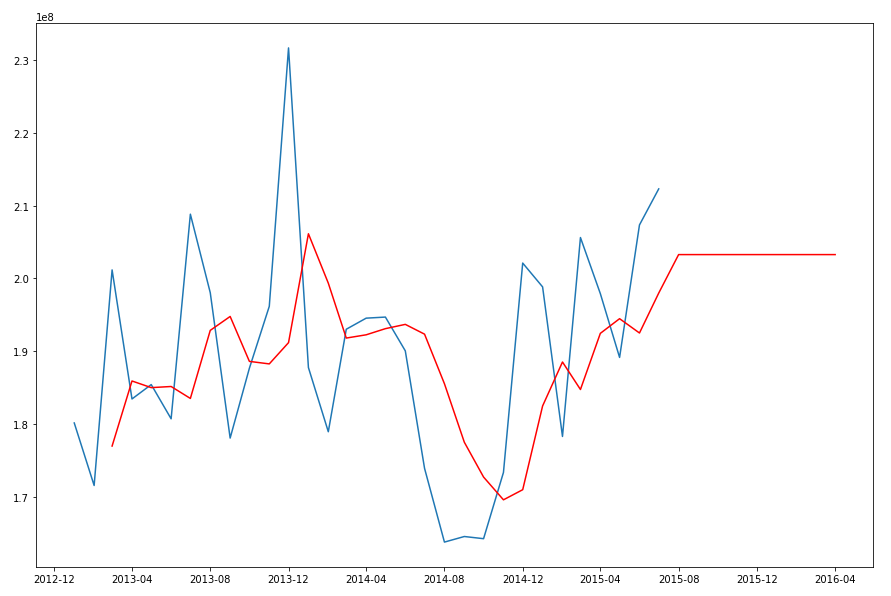
 The blue line contains the original data values and the red line contains the predicted values. The predictions are very similar to those produced using Holt-Winters in Python.
The blue line contains the original data values and the red line contains the predicted values. The predictions are very similar to those produced using Holt-Winters in Python.