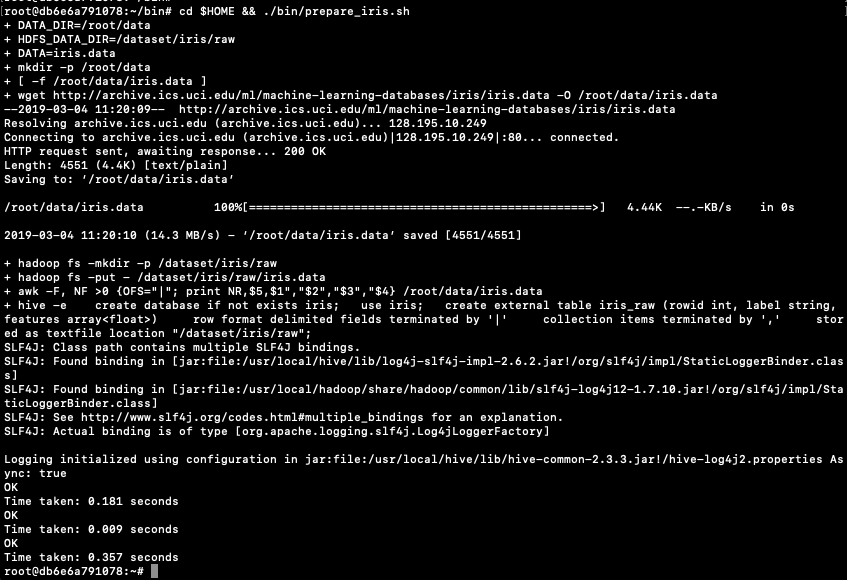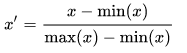
Using the IRIS data set as the data set (and loaded in previous post), the first thing we need to find is the minimum and maximum values for each feature.
select min(features[0]), max(features[0]),
min(features[1]), max(features[1]),
min(features[2]), max(features[2]),
min(features[3]), max(features[3])
from iris_raw;
we get the following results.
4.3 7.9 2.0 4.4 1.0 6.9 0.1 2.5
The format of the results can be a little confusing. What this list gives us is the results for each of the four features. For feature[0], sepal_length, we have a minimum value of 4.3 and a maximum value of 7.9. Similarly, feature[1], sepal_width, min=2.0, max=4.4 feature[2], petal_length, min=1.0, max=6.9 feature[3], petal_width, min=0.1, max=2.5 To use these minimum and maximum values, we need to declare some local session variables to store these.
set hivevar:feature0_min=4.3;
set hivevar:feature0_max=7.9;
set hivevar:feature1_min=2.0;
set hivevar:feature1_max=4.4;
set hivevar:feature2_min=1.0;
set hivevar:feature2_max=6.9;
set hivevar:feature3_min=0.1;
set hivevar:feature3_max=2.5;After setting those variables we can now write a SQL SELECT and use the add_bias function to perform the calculations.
select rowid, label,
add_bias(array(
concat("1:", rescale(features[0],${f0_min},${f0_max})),
concat("2:", rescale(features[1],${f1_min},${f1_max})),
concat("3:", rescale(features[2],${f2_min},${f2_max})),
concat("4:", rescale(features[3],${f3_min},${f3_max})))) as features
from iris_raw;
and we get
> 1 Iris-setosa ["1:0.22222215","2:0.625","3:0.0677966","4:0.041666664","0:1.0"]
> 2 Iris-setosa ["1:0.16666664","2:0.41666666","3:0.0677966","4:0.041666664","0:1.0"]
> 3 Iris-setosa ["1:0.11111101","2:0.5","3:0.05084745","4:0.041666664","0:1.0"]
...Other feature scaling methods, available in Hivemall, include L1/L2 Normalization and zscore.



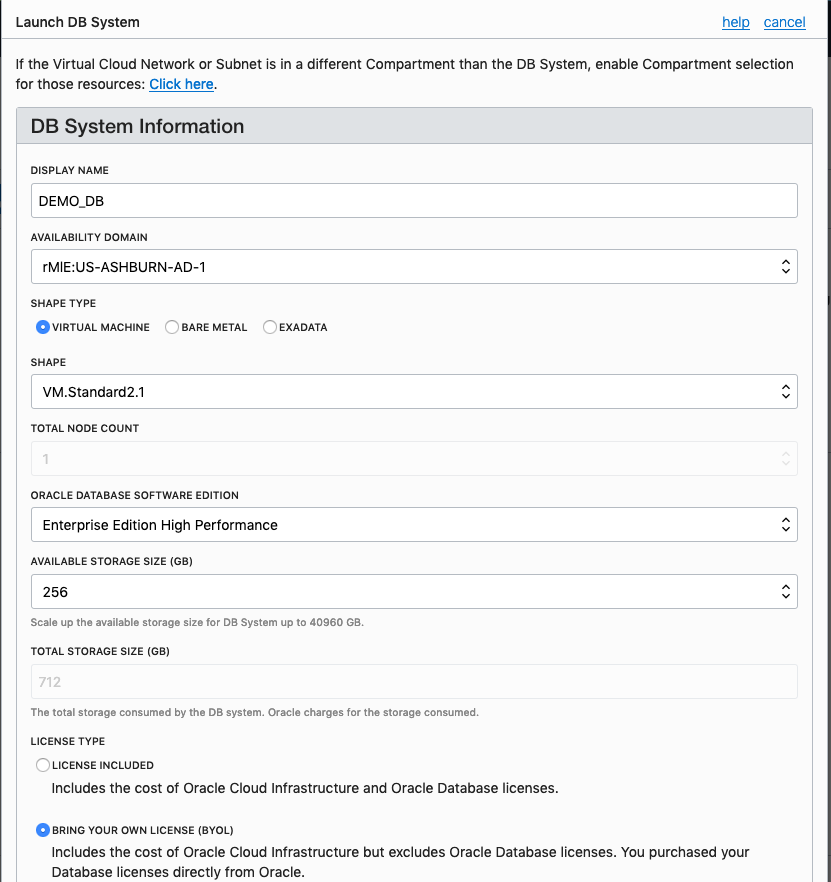
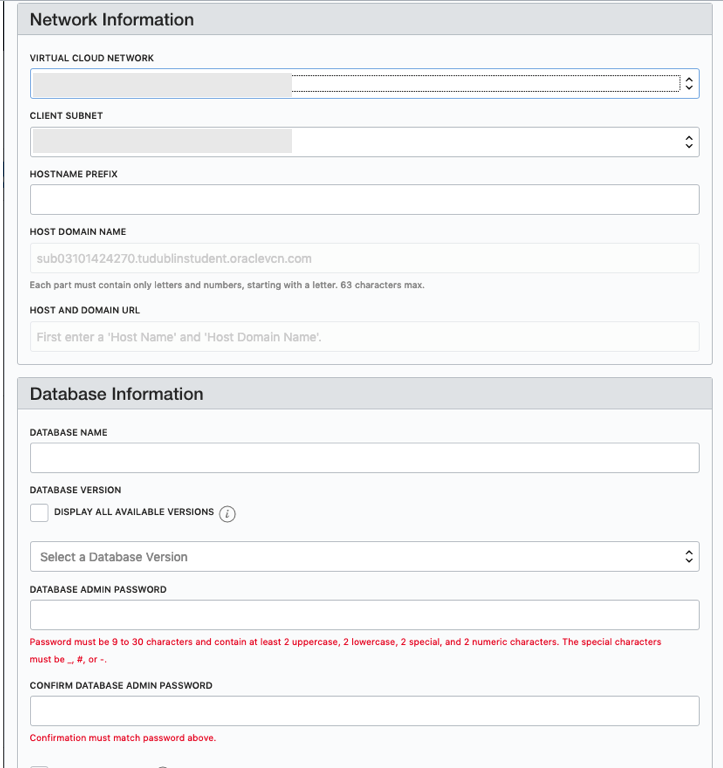

 From that screen, click on Default Security List, and then click on the 'Edit All Rules' button at the top of the next screen.
Add a new rule to have a 'Destination Port Range' set for 1521
From that screen, click on Default Security List, and then click on the 'Edit All Rules' button at the top of the next screen.
Add a new rule to have a 'Destination Port Range' set for 1521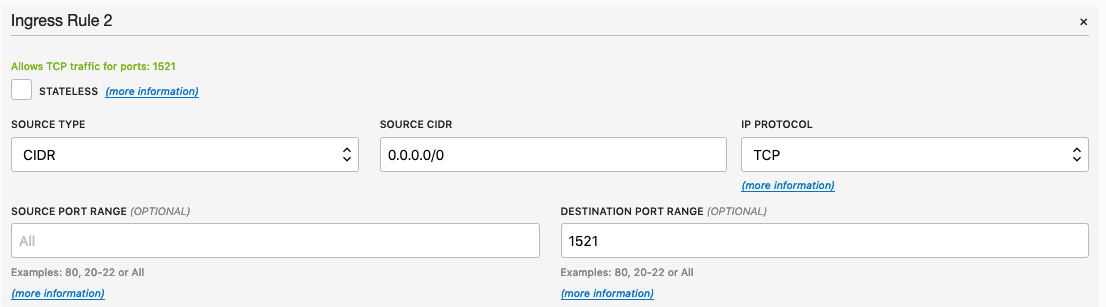


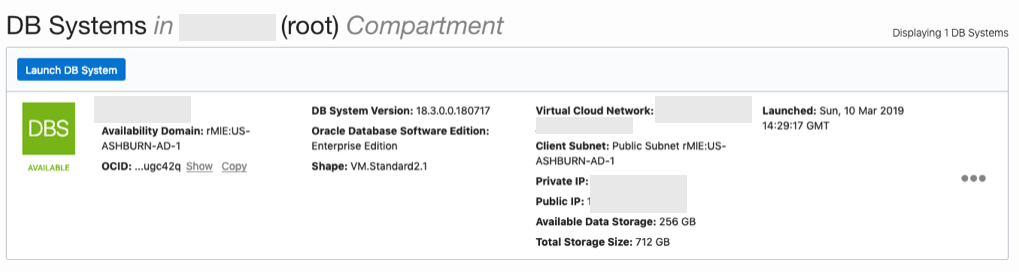
 Until everything is completed.
Until everything is completed.
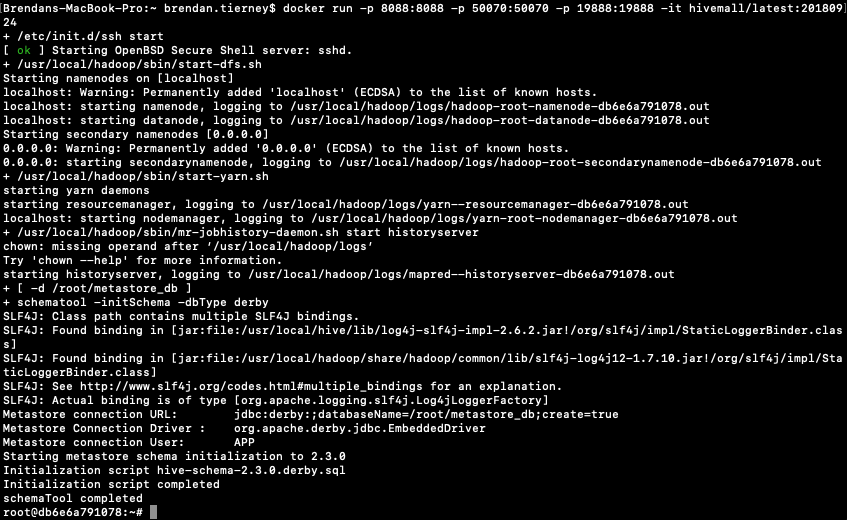
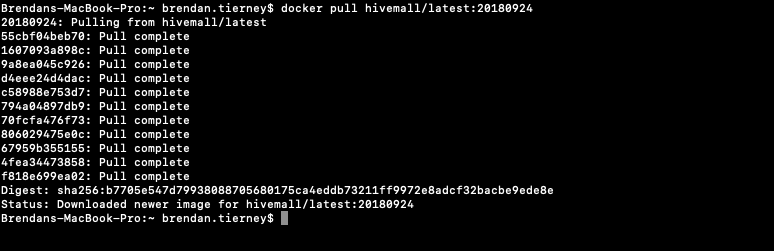 This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run
This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run