When preparing data for input to machine learning algorithms you may have to perform certain types of data preparation.
In most enterprise solutions all or most of these tasks are automated for you, but in many languages they aren't. The enterprise solutions are about 'automating the boring stuff' so that you don't have to worry about it and waste valuable time doing boring, repetitive things.
The following examples illustrates a number of ways to record categorical variables into numeric. There are a number of approaches available, and it is up to you to decide which one might work best for your problem, your data, etc.
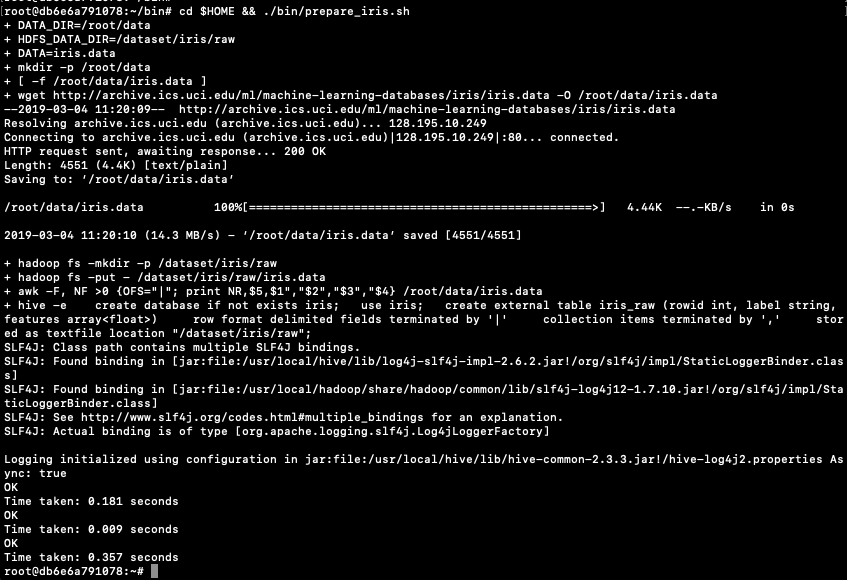
Let's begin by loading the data set to be used in these examples. It is a Video Games reviews data set.
# perform some Statistics on the items in a panda
import pandas as pd
import numpy as np
import matplotlib as plt
videoReview = pd.read_csv('/Users/brendan.tierney/Downloads/Video_Games_Sales_as_at_22_Dec_2016.csv')
videoReview.head(10)

What are the data types of each variable
videoReview.dtypes

We don't want to work with all the data in these examples. We just want to concentrate on the categorical variables. Let's us create a subset of the dataframe to contains these.
df = videoReview.select_dtypes(include=['object']).copy()
df.head(10)

Now do a little data clean up by removing NaN (nulls)
df.dropna(inplace=True)
df.isnull().sum()

df.describe()

The above image shows the number of unique values in each of the variables. We will use Platform, Genre and Rating for the variable example below.
Let us chart these variables.
#check the number of passengars for each variable
import seaborn as sb
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = 10, 8
sb.countplot(x='Platform',data=df, palette='hls')

sb.countplot(x='Genre',data=df, palette='hls')

sb.countplot(x='Rating',data=df, palette='hls')
 1-One-hot Coding
1-One-hot Coding
The first approach is to use the commonly used one-hot coding method. This will take a categorical variable and create a set of new variables corresponding with each distinct value in the variable, and then populate it with a binary value to indicate the original value.
#apply one-hot-coding to all the categorical variables
# and create a new dataframe to store the results
df2 = pd.get_dummies(df)
df2.head(10)

As you can see we now have 8138 variables in the pandas dataframe!
That is a lot and may not be workable for you. You may need to look at some feature reduction methods to reduce the number of variables.
2-Find and Replace
In this example we will simple replace the values with defined values.
Let's have a look at values in the Ratings variable and their frequencies.
df['Rating'].value_counts()

The last 4 values listed have very small number of occurrences.
We will group these into having one value/category.
find_replace = {"Rating" : {"E": 1, "T": 2, "M": 3, "E10+": 4, "EC": 5, "K-A": 5, "RP": 5, "AO": 5}}
df.replace(find_replace, inplace=True)
df.head(10)

Now plot the newly generated rating values and their frequencies.
sb.countplot(x='Rating',data=df, palette='hls')
 3 - Label encoding
3 - Label encoding
With this technique where each distinct value in a categorical variable is converted to a number.
In this scenario you don't get to pick the numeric value assigned to the value. It is system determined.
#let's check the data types again
df.dtypes

Our categorical variables are of 'object' data type. We need to convert to a category data type.
In this example 'Platform' as it has a large-ish number of values and we want a quick way of converting them we can illustrate this by creating a new variable.
df["Platform_Category"] = df["Platform"].astype('category')
df.dtypes

Now convert this new variable to numeric.
df["Platform_Category"] = df["Platform_Category"].cat.codes
df.head(20)

The number assigned to the Platform_Category variable is based on the alphabetical ordering of the values in the Platform variable. For example,
df.groupby("Platform")["Platform"].count()
 4-Using SciKit-Learn transform
4-Using SciKit-Learn transform
SciKit-Learn has a number of functions to help with data encodings. The first one we will look at is the 'fit_transform' function.
This will perform a similar task to what we have seen in a previous example.
#Let's use the fit_tranforms function to encode the Genre variable
from sklearn.preprocessing import LabelEncoder
le_make = LabelEncoder()
df["Genre_Code"] = le_make.fit_transform(df["Genre"])
df[["Genre", "Genre_Code"]].head(10)

And we can see this comparison when we look at the frequency counts.
df.groupby("Genre_Code")["Genre_Code"].count()

df.head(10)

And now we can drop the Genre variable from the dataframe as it is no longer needed. BUT you will need to have recorded the mapping between the original Genre values and the numeric values for future reference.
df = df.drop('Genre', axis=1)
df.head(10)
 5-Using SciKit-Learn LabelEndcoder
5-Using SciKit-Learn LabelEndcoder
SciKit-Learn has a binary label encoder and it can be used in a similar way to the previous example and also similar to the 'get_dummies' function.
from sklearn.preprocessing import LabelBinarizer
lb_style = LabelBinarizer()
lb_results = lb_style.fit_transform(df["Rating"])
lb_df = pd.DataFrame(lb_results, columns=lb_style.classes_)
lb_df.head(10)

These can now be joined with the original dataframe or a with a subset of the original dataframe to form a new dataframe consisting of the required variables.
As you can see, from the following, there are several other data pre-processing functions available in SciKit-Learn.






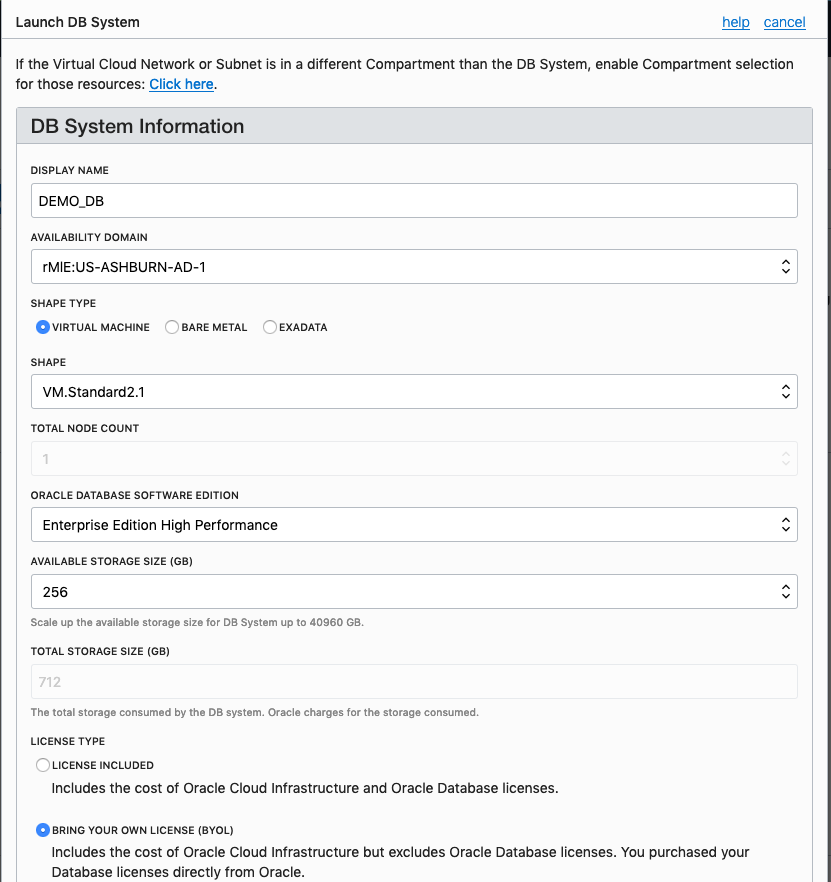
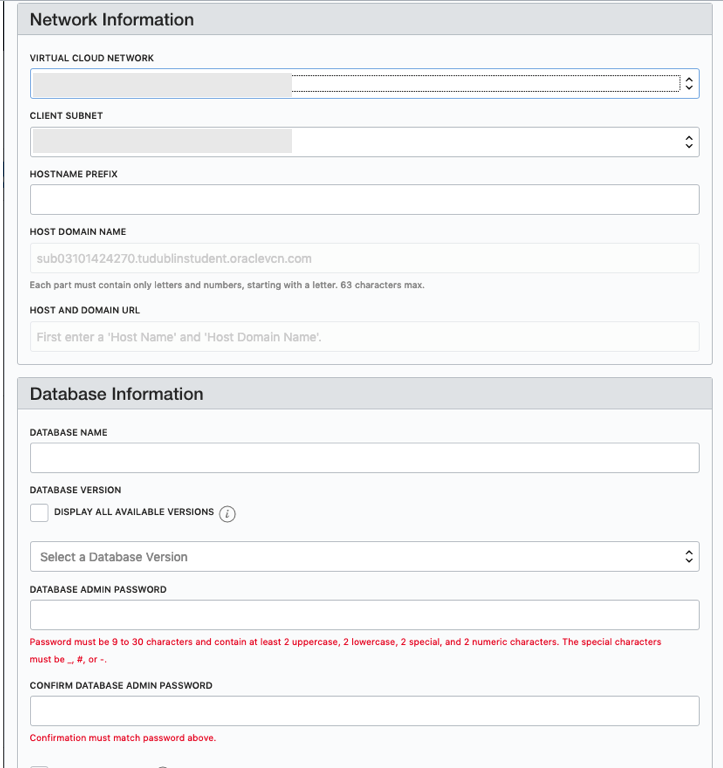

 From that screen, click on Default Security List, and then click on the 'Edit All Rules' button at the top of the next screen.
Add a new rule to have a 'Destination Port Range' set for 1521
From that screen, click on Default Security List, and then click on the 'Edit All Rules' button at the top of the next screen.
Add a new rule to have a 'Destination Port Range' set for 1521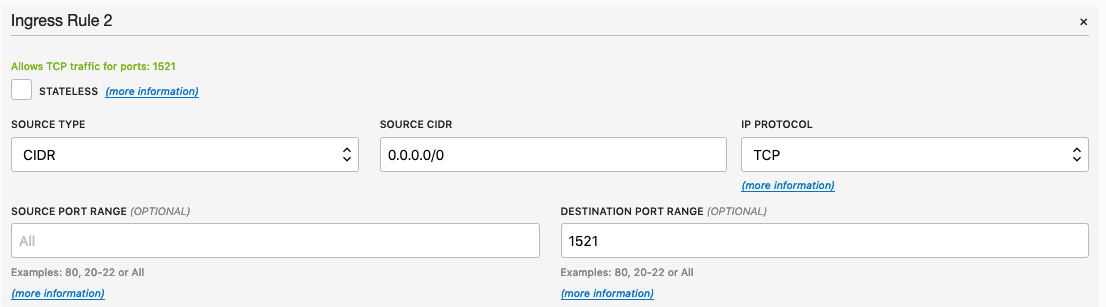


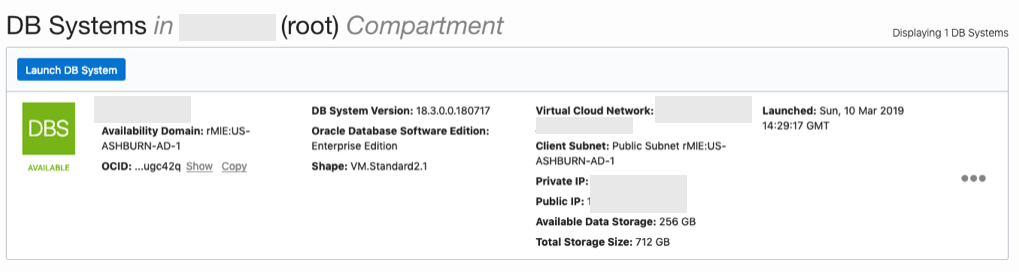
 Until everything is completed.
Until everything is completed.
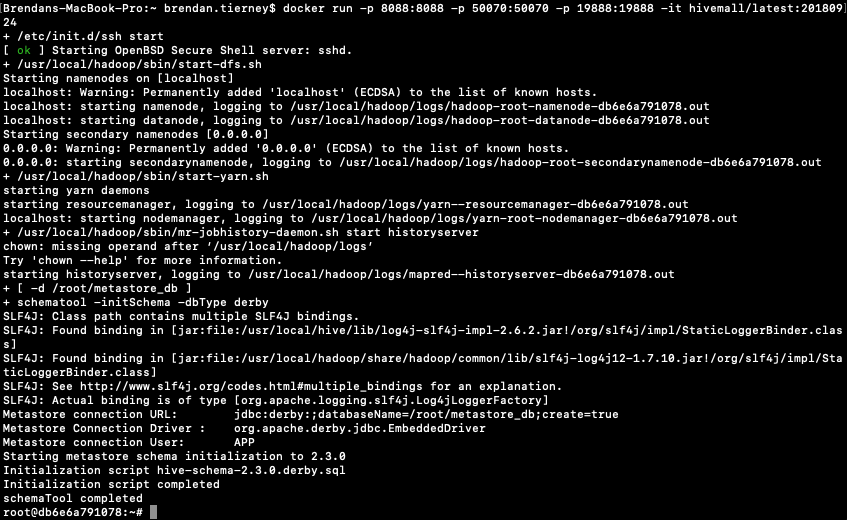
 This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run
This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run