But how can we calculate the moving average in SQL?
Well, there isn't a function to do it, but we can use the windowing feature of analytical SQL to do so. The following example was created in an Oracle Database but the same SQL (more or less) will work with most other SQL databases.
SELECT month,
SUM(amount) AS month_amount,
AVG(SUM(amount)) OVER
(ORDER BY month ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS moving_average
FROM sales
GROUP BY month
ORDER BY month;
This gives us the following with the moving average calculated based on the current value and the three preceding values, if they exist.
MONTH MONTH_AMOUNT MOVING_AVERAGE
---------- ------------ --------------
1 58704.52 58704.52
2 28289.3 43496.91
3 20167.83 35720.55
4 50082.9 39311.1375
5 17212.66 28938.1725
6 31128.92 29648.0775
7 78299.47 44180.9875
8 42869.64 42377.6725
9 35299.22 46899.3125
10 43028.38 49874.1775
11 26053.46 36812.675
12 20067.28 31112.085
In some analytic languages and databases, they have included a moving average function. For example using HiveMall on Hive we have.
SELECT moving_avg(x, 3) FROM (SELECT explode(array(1.0,2.0,3.0,4.0,5.0,6.0,7.0)) as x) series;If you are using Python, there is an inbuilt function in Pandas.
rolmean4 = timeseries.rolling(window = 4).mean()

 Until everything is completed.
Until everything is completed.
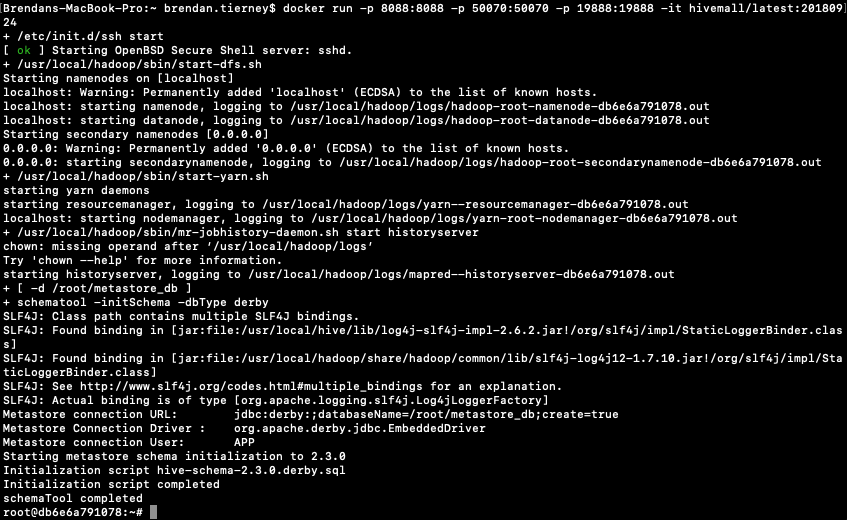
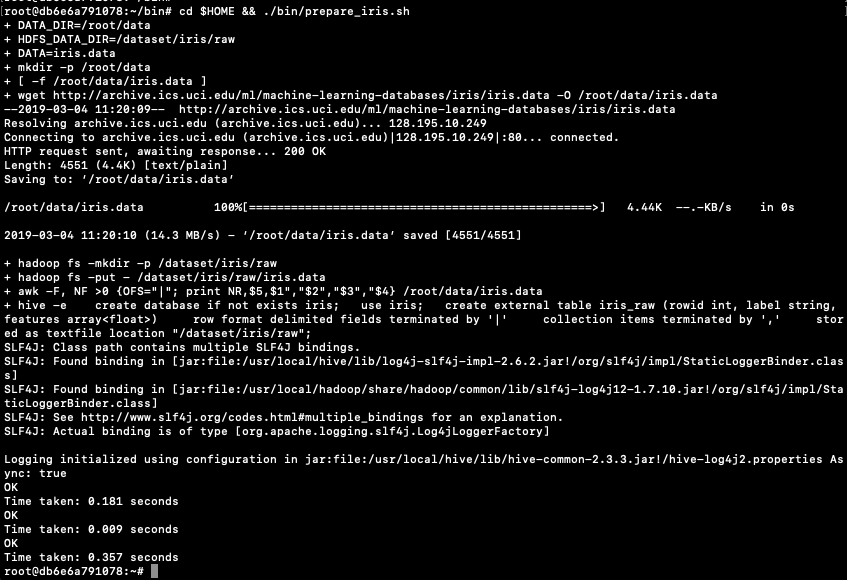
 This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run
This docker image has HDFS, Yarn and MapReduce installed and running. This will require the exposing of the ports for these services 8088, 50070 and 19888.
To start the HiveMall docker image run